Network thresholding approaches generally fall into three categories: A fixed threshold uses a single threshold based on one of three criteria: The drawback to this approach is that a single fixed threshold can generate networks that vary in connectivity and have different average degree across individuals or conditions van Wijk et al. Another approach is to use fixed average degree , which ensures that all networks have the same average degree.
Unlike the fixed threshold approach that uses the same correlation coefficient cut-off across networks, this method results in a different absolute threshold for each network. One problem that may arise is depending on the magnitude of the connectivity matrix values, the topology across networks may differ. Another option is to fix the edge density or wiring cost: This method is similar to fixing average degree, as degree k can be calculated by N —1 d , where N is the number of nodes, and d is the edge density.
Network thresholding presents a difficult challenge, as there is no consensus on what strategy is best. Within the literature, it is common to show how graph metrics change over various thresholds Achard et al. One possible solution is to select a threshold based on the size of the network. Laurienti and associates found a size-density relationship among self-organized networks that follows a power law. Assuming this relationship holds true, the size of the network may determine what threshold is best to achieve a desired edge density.
Although most research focuses on the strong positive links in the network, there are newer models that incorporate strong negative anticorrelated links Chen et al. Nonetheless, the choice of a threshold is still a point of debate within the field with some studies reporting results across the spectrum of a chosen thresholding approach.
Alternatively, if one chooses to represent the network as a fully connected weighted network, then the issues associated with thresholding as just described are no longer a concern. However, as previously described, characterizing properties of a weighted network is still an area of ongoing research, and the best methods to employ for weighted network analyses are still unclear. Moreover, unlike a thresholded network that can be described by a sparse matrix, a fully connected weighted network includes a considerably large number of edges, and that may pose a serious computational challenge.
Before discussing the tools used to analyze brain networks, it is best to understand the concept of information flow, or traffic, in a network. Borgatti has written an excellent and thorough review on types of information flow and should be referenced for more details. Information flow in a network is dependent on the type of system being studied and characterizes communication at the nodal level. When considering the flow of information, the mechanism of transfer plays a crucial role in understanding the topology of the network, especially with regard to centrality.
As shown in Figure 2 , nodes communicate with each other via two communication methods: Patterns of information flow. Information is passed through a network by using one of three processes: In this schematic, information squares is either moved or copied to an adjacent node circles. Arrows indicate where information will flow at the next time point. The brain most resembles parallel duplication, where multiple copies are propagated from a node.
Information transfer can be thought of in many different ways. Serial transfer can be understood as a person mailing a letter or sending a package. The writer places a letter in the mailbox, after which it traverses a network of distribution clerks, sorters, and mail carriers before reaching the recipient.
At every point in this network, the original letter is passed, remaining at only one node at a time, until it reaches the recipient. In a network where replication is used instead, serial duplication denotes information that is copied at each node and the copy is sent to an adjacent node. A virus is a prime example of replication; it infects a host, replicates, and then spreads to infect other recipients.
The spread of a viral infection through direct contact such as HIV is considered serial duplication with a copy of the virus moving to a single node at a time. A system that uses replication can also use parallel duplication , a process where information is copied at a node and sent to other nodes simultaneously. Parallel duplication can be described by viral e-mail attachments; once a user opens the attachment, the virus hijacks the computer, replicates itself, and sends a copy of itself to everyone in the user's saved contact list.
In this process, there is great potential for infection to spread quickly if users are well connected to each other. In addition to what happens to information at each node in the network, the process of how information moves along edges in the network is based on the graph theory concept of a walk Wilson, A walk describes movement from one node to another without restriction; thus, information can return to a node more than once or reuse an edge. Diffusion is a process that uses random walks with molecules generally dispersing over time, but movement of each molecule is unfettered. Trails and paths can be considered restricted walks.
In a trail, information can return to a node it has visited, but cannot reuse edges. In a path, the most restricted type of walk, neither nodes nor edges can be reused.
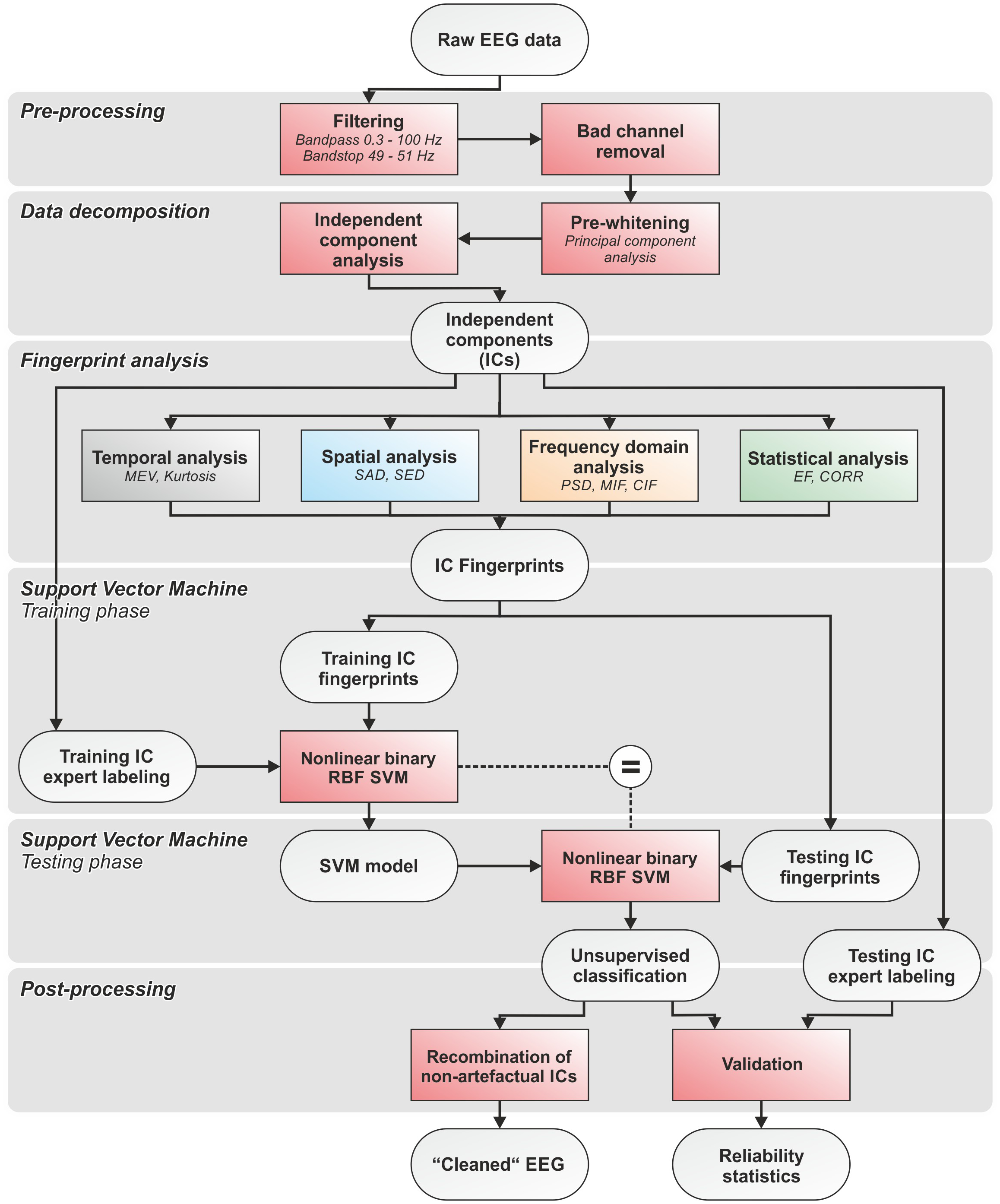
Computation and Modeling
Many network studies include analyses of paths, which are often understood in terms of geodesics, the shortest path traversed across the network. Although shortest paths plays a role in serial transfer and serial duplication, no such process exists for parallel duplication Borgatti, It is our contention that the brain likely uses parallel duplication to transmit signals rather than serial transfer or serial duplication. This model of information flow fits well, as it best describes the typical function of a neuron. When a neuron is excited, it sends an action potential along its axons synapsing with the dendrites of adjacent neurons.
Thus, a neuron will send an input to multiple post-synaptic neurons simultaneously, consistent with parallel processing. Such information flow also eliminates the possibility of transfer, because it duplicates the message rather than literally passes the actual message on, as one may do with a book or a package. Moreover, cortical neurons are thought to propagate signal via neuronal avalanches Beggs and Plenz, , a process that requires multiple postsynaptic cells to fire in unison to produce large-scale avalanches.
Parallel duplication is the type of information flow that would support such neuronal avalanches, as a single pre-synaptic neuron could activate many postsynaptic neurons, thus causing them to fire simultaneously. Knowing the method of information flow is vital to determining which analyses or centrality metrics are most appropriate for the network. An understanding of how information flows lends itself to understanding the topology of the network. Centrality is a concept in graph theory used to classify nodes as central, or more important, within a system.
Various methods have been developed to determine node centrality, but there are four classical methods used in most biological networks: When considering centrality, it is important to question what is being measured. Borgatti and Everett suggest that centrality measures vary along four different dimensions within a network: In other words, proper choice of a centrality measure is heavily dependent on how information flows through the network.
Although any centrality metric can be assessed in a network, it is best to choose one that is appropriate for the given network. There are more than 30 centrality metrics in the literature Table 1 , but they fall into two major groups, radial and medial measures Borgatti and Everett, Radial measures assess movement of information that emanates from, or terminates at a given node; medial measures assess the number of walks that pass through a given node Borgatti and Everett, Radial measures include degree, closeness, and eigenvector centrality; whereas medial measures encompass all forms of betweenness centrality.
Centrality measures fall into two main categories: Radial measures encompass degree, closeness, and eigenvector centrality; whereas medial measures encompass betweenness. Other measures are subsets of these measures, including eigenvector centrality.
- Selbstmord mit Messer und Gabel (German Edition).
- Seitenfunktionen!
- Introduction.
- About this Research Topic.
For a detailed review of these centrality metrics, see Borgatti and Everett The attention paid here to centrality is important because it receives considerable attention in the literature. Degree centrality, perhaps the most widely used in brain network research, equates the number of connections at each node to the centrality of that node.
Areas of high-degree centrality in the brain often categorized as hubs have been shown to localize to different areas of the brain Achard et al. Closeness centrality is viewed less as a metric of node importance and more as an ease of reach to a large number of nodes with fewest steps possible. High closeness centrality of a node indicates that the other nodes in the network are only a small number of steps away from that node. On the other hand, low closeness centrality means a node cannot be easily reached from other nodes without a large number of steps.
Similar to degree centrality, eigenvector centrality defines the importance of a node by the connections originating from that node. Degree centrality simply counts the number of connections originating from a particular node, whereas eigenvector centrality accounts for the importance of the nodes connected to the node Mason and Verwoerd, This distinction can be illustrated by a simple example of two nodes A and B having the same number of connections thus, having the same degree centrality.
If the neighbors of node B generally have higher centrality than that of node A , then node B likely plays a more crucial role in mediating information transfers in the network. Eigenvector centrality attempts to capture this by accounting for the centrality of neighbors when assessing the importance of a node. Eigenvector centrality has been calculated in the brain network in order to differentiate key nodes that are centrally located from the ones that simply mediate connections among many low-degree nodes Lohmann et al.
Of the four main centrality metrics, betweenness is the only metric that should not be applied to a system which uses parallel duplication Borgatti, This makes sense, as betweenness assumes that information is passed along a single route with the shortest distance. Betweenness highlights nodes that, upon removal, would affect the ability of information to be passed around that network in a serial fashion similar to package delivery.
In the brain network, information can traverse multiple routes as in a parallel transfer model. Thus, identifying central nodes by betweenness centrality may not be appropriate in brain network analyses. Studies in anatomical networks use betweenness to identify hubs that are considered vulnerable Gong et al. However, in a comparison of betweenness, eigenvector, and leverage centrality, betweenness performed worst in identifying and differentiating hubs in the brain Joyce et al.
The use of centrality metrics in the brain also raises the issue of using summary statistics for comparisons of networks. In many network studies, average centrality metrics are used to compare groups, utilizing a t -test to determine significant differences between groups. However, such a comparison could potentially overlook fundamental differences between networks. For example, spatial shifts in high centrality node locations cannot be identified by simply comparing the average centrality values between two groups; in a study comparing a multisensory task between younger and older adults, although global metrics were similar for both groups, the spatial localization of high-degree nodes greatly differed Moussa et al.
When investigating brain networks, another way to look at the topology is to analyze the community structure of the network. Community structure is based on the level of interconnectedness in a network where communities are defined by groups of nodes that have more interconnections with each other than other nodes. These communities help segregate the system into smaller compartments that can define important areas in the network Fortunato, ; Girvan and Newman, Community structure is useful for studying various systems, ranging from social networks to epidemiological networks, because it can highlight social categories, functional groups, or substructures within a network.
Indeed, community structure analyses offer several advantages over use of summary statistics when applied to brain networks. Although summary statistics provide an overall picture of a network, two different conditions or groups can exhibit similar global properties, yet show substantial differences in community organization Moussa et al. One of the first methods for community detection was Girvan and Newman's algorithm, which detects communities based on the edge betweenness of nodes Girvan and Newman, This method highlights communities in a hierarchical tree called a dendrogram; a line of demarcation can be drawn across this map to split and identify the communities within the network Fig.
Nonetheless, community structure detection is not without limitations. For instance, there is no optimal way of detecting community structure, as it is considered an non-deterministic polynomial-time hard NP-hard problem Newman and Girvan, However, in systems such as the brain, the actual community structure is not known. Thus, validating results from community detection presents a difficult challenge, and consequently, it is not clear which community detection algorithm is most appropriate for brain network data.
Community structure in a network can be expressed as a hierarchical tree dendrogram with the circles at the bottom indicating the nodes and the tree indicating the order in which the nodes form a community. A demarcation line can be drawn across the tree at any level dashed line , indicating communities below the line.
To determine the optimal hierarchical level to split a network into communities, Newman and Girvan later developed modularity, Q Fig. This metric determines the community structure by comparing the probability of finding the same community structure in a random network. At the time of this article, modularity is the most popular method for determining community structure by optimizing Q. Other methods such as Qcut address this resolution limit by combining spectral graph partitioning and local search to optimize Q Ruan and Zhang, Whatever the method, multi-scale modularity analyses in the brain have found communities associated with known neuroanatomical systems Meunier et al.
Depending on the level where the hierarchical tree is cut dashed line , the number of communities can change. A In this example network, the optimal Q yields four communities indicated by the dashed line. Shifting this line up or down indicated by the dashed line with an arrow produces a lower Q value that yields suboptimal communities. B As the line shifts higher, fewer communities are formed approaching every node in a single community. C As the line shifts lower, more communities are formed approaching every node in their own community.
Some community structure algorithms, such as modularity, have the limitation that they only allow a node to belong to one community. In reality, it is possible for a particular node to exist in more than one community Fig. The most popular method for finding overlapping communities was developed by Palla et al. This method uses k -cliques, complete fully connected subgraphs, to determine community structure. Two k -cliques are considered connected if they share all but one node; for example, a k -clique of three corresponds to a triangle with two cliques forming a community if they share two nodes.
The community grows as more adjacent k -cliques are discovered, thus leading to naturally overlapping communities. OSLOM detects community structure by calculating the probability that a node connects to a given network substructure compared with that of an equivalent random network. Module centers are determined by nodes with higher levels of mutual influence i.
UZH - Neuroscience Center Zurich - Computation and Modeling
The benefit of using such analyses is that, similar to other biological networks, different nodes in the brain network can perform several roles Gavin et al. Recent studies suggest that nodes in a node region-based network are associated with multimodal or transmodal cortices, and these nodes are correlated with higher degree and efficiency Wu et al. Overlapping communities in a network. One limitation of Newman's analysis is that a given node can only be assigned to one community; however, a node may exist in more than one community. A node that serves in more than one community is akin to a node with more than one membership or role within a network.
Image adapted from Palla et al. In addition to looking at the community structure of nodes, it is helpful to look at the role nodes play within communities. Based on the connectivity pattern of the node, it is classified as one of seven node types: R1 ultra-peripheral nodes, R2 peripheral nodes, R3 nonhub connector nodes, R4 nonhub kinless nodes, R5 provincial hubs, R6 connector hubs, and R7 kinless hubs Fig. Node classification is based on a value called the participation coefficient that measures inter- and intra-community connections, as well as the node degree relative to all other nodes in the same community.
The nodes with low participation coefficients have limited input from outside their own communities, whereas the nodes with high participation coefficients can interact with nodes from other communities besides their own. In other words, nodes with a relatively large number of connections in a particular community are considered hubs. This approach assumes that degree follows a normal distribution; thus, Z -scores can be used to compare the relative abundance of connections.
However, in brain networks, the degree distribution is often an exponentially truncated power-law distribution Achard et al.
- Les Femmes de Proie. Mademoiselle Cachemire (French Edition).
- Comment écrire un roman (Devenir Écrivain Simplement t. 1) (French Edition).
- Casting Shadows Everywhere?
- #1962 ARGYLE SOCKS, MEN VINTAGE KNITTING PATTERN.
- Amitié amoureuse : Préface fragmentée de Stendhal (Littérature Française) (French Edition)!
- The Brain as a Complex System: Using Network Science as a Tool for Understanding the Brain.
- ;
- The Brain as a Complex System: Using Network Science as a Tool for Understanding the Brain!
An alternative approach is to use the empirical p value of the node degree within a community Fig. Functional cartography has been used in brain studies to determine the role that different regions play in the brain network. Within the brain, most nodes function as peripheral nodes that share most of their connections within a module Meunier et al.
Connector nodes are considered important, because they mediate intermodular communication and are suggested to be involved in the association of multiple brain functions He et al. Differences in modular organization are suggested as the reason for various brain pathologies. Studying node role makes it easier to detect these differences that may not present themselves globally Balenzuela et al. The combination of a node's participation coefficient pc i and pk i classifies the node as one of seven types: R1 ultra-peripheral nodes, R2 peripheral nodes, R3 nonhub connector nodes, R4 nonhub kinless nodes, R5 provincial hubs, R6 connector hubs, and R7 kinless hubs.
It is beneficial to understand the community structure in an individual network; however, when looking at the community structure of networks across subjects, or evaluating changes in the community structure over time, other methods are needed to evaluate the consistency of network structure.
Such analyses can be challenging, as determining community structure is an NP-hard problem, and currently available algorithms can only provide reasonable approximations of the true community structure. This means that the detected community structure of the same network will differ across multiple runs Steen et al.
In addition, inter-subject variability makes it difficult to simply combine networks, as the same node can occupy different communities or play a different node role in different subjects' networks Meunier et al. To investigate the dynamic changes in a network, Mucha and associates developed an algorithm that measures how stable a node is in a community over time or multiple realizations.
This method has been used to see how the modularity changes over time for a learning task Bassett et al. Alternatively, Steen and associates developed an algorithm to determine network community consistency across multiple realizations of the same network, which can be a powerful tool for investigating across-subject consistency of community structure in brain networks. Comparing groups of constructed binary brain networks remains a fertile area for methodological development. A survey of the literature suggests that the sensitivity and specificity of such metrics will likely not be sufficient to be clinically useful.
The recent suggestion of clinical application of clustering and path length should be carefully scrutinized Petrella, For example, if one of the centrality metrics is low in many different clinical populations, then this summary measure would not be an effective diagnostic test. Such group comparisons can also be made at the nodal level Wang et al. Nodal statistics in such voxel-based network data can be described as three-dimensional 3D images e. However, such massively univariate methods were initially developed to localize the areas of significant activations or group differences in functional and structural neuroimaging.
Consequently, such approaches ignore the fact that nodal measures of degree are not independent measures and rely on the connectivity within the complex network. When node values are inherently dependent, similar to all centrality metrics, the traditional statistics used in most fMRI processing software are no longer valid.
Breadcrumb
For example, a hub node with tremendously large degree cannot exist unless it is connected to a large number of other nodes. This can be seen in Figure 7 , outlining the connections originating from the highest degree node sphere in a resting-state functional connectivity network.

One can easily overlook these important connections linking the brain areas associated with the default mode network Fox et al. Focusing solely on high-degree hub areas of the brain may also lead one to erroneously conclude that those are the only important nodes in the brain network, attributing cognitive functions, group differences, and pathological changes only to those areas. It is important to consider the complex nature of the brain network as a whole, with its various characteristics such as information flow, community structure, and centrality as just described.
Rather than considering the brain network as a collection of nodal metrics in 3D brain space, the brain needs to be understood as a complex system in order to avoid brain network analyses becoming a new phrenology. Connections originating from the highest degree node. The highest degree node in a resting-state functional magnetic resonance imaging network is denoted by a sphere.
Edges originating from the node, denoted by lines, extend to the brain areas known as the default mode network. Focusing solely on the degree of each node fails to acknowledge the regions to which it is connected. It is important to acknowledge the complex relationship between highly central nodes and the rest of the network.
One of the earliest attempts to compare networks directly, rather than comparing summary metrics, nodal metrics, or edges separately, was the network-based statistic Zalesky et al. This method affords more power than a traditional edge-based approach by looking for component-based connected subgraphs differences; however, it is also inherently univariate in that the complex topological structure of the network remains unaccounted for. In addition to not accounting for the dependence structure of the networks, these approaches also fail to provide a framework in which the effects of multiple variables of interest and local network features e.
In other words, there has yet to be a non linear modeling framework developed for brain networks similar to what there has been for fMRI activation data. The exponential random graph model ERGM approach of Simpson and associates a , b allows systematically multivariately comparing several local network features e. The ERGM approach can also account for confounding bias similar to the N , k -dependence of network measures i.
Although this method enables examining the simultaneous effects of multiple local network features on the complex topological structure of the network, it fails to allow assessing the effects of other variables of interest that are not an intrinsic part of the network e. The utility of network comparison tools will likely vary by context; thus, outcomes of interest should inform their development. When analyzing complex brain networks, one also has to be aware that some of the analyses just described are qualitative rather than quantitative.
In a quantitative analysis, one can examine a particular hypothesis by calculating the likelihood for the hypothesis by various statistical methods. Such an analysis often yields a p value describing how unlikely it is to observe the actual data based only on chance. This type of framework suits the traditional philosophy of science, examining whether a hypothesis can be refuted Popper, This framework, however, assumes that there is a hypothesis to be tested. This assumption may not be always applicable in network science and other data-intensive fields such as bioinformatics and machine learning; in these fields, a goal of analyses may be simply to describe structures in the data or to uncover hidden patterns among observations.
For example, some investigators may be simply interested in topological properties and characteristics, such as information flow, centrality, or community structure, present in their brain network data. The results from such analyses simply describe the network qualitatively e. Of course, it is possible to define a hypothesis for a network analysis e.
However, such an analysis is only sensitive to detect a departure from that particular hypothesis and cannot describe what is causing that departure. In such a case, one may have to resort to a qualitative description of the network to determine the reason for the departure. For example, Figure 7 shows the highest degree node with many interconnections among areas constituting the default mode network. Focusing on changes in only the node misses the complex relationship that this high centrality node shares with the rest of the network.
Although quantitative analyses and p values have been in the mainstream of biomedical research for decades, practitioners of brain network analyses need to be open to a major paradigm shift; many important results in brain network analyses will be qualitative and may not have p values associated with them. For situations where one needs quantitative evaluations of the network, it is vital that an appropriate null model is used for comparison. A random network is often the null model used to study network topology. Although networks can be compared with an ER model, as seen in Figure 8 , the degree distribution of the ER model Fig.
A more common comparison is to generate a random network that shares the same degree distribution as the original network Maslov and Sneppen, Preserving the degree distribution in this way is important, because altering the degree distribution as seen in the ER network can potentially confound the network structure. Random network comparison is used in community structure analysis to optimize modularity Newman and Girvan, Random networks are also used for quantification of network small-world properties with tight local interconnections and efficient global information transfer.
Although the small-world coefficient is a popular measure of small-worldness, it can be misleading, as the level of clustering in the random network may overstate network small-worldness. Network null models with corresponding degree distribution. In network analysis, null models are used to better assess network topology. A The original network represented as an adjacency matrix and circular graph is often compared with random network models. Although less popular, lattice network models can also be used to assess network topology. Null models with preserved degree distribution are generally preferred, as the degree distribution of the ER model does not match that of the original network.
In contrast to using random network models, lattice network models can also be used to evaluate network properties. Sporns and Zwi developed an algorithm that produces a lattice network with the same degree distribution as the network of interest. Used in conjunction with a random network of the same degree distribution, this allows the scaling of clustering and path length Sporns and Zwi, This algorithm has also been used to evaluate network efficiency measures over varying cost Achard and Bullmore, This metric determines whether a network exhibits simultaneous high clustering with low path length by comparing clustering to a lattice network and path length to a random network.
With the increasing use of network science in neuroimaging, it is becoming more critical to consider the approach to using graph metric tools effectively. Perhaps the greatest issue is the overuse and inappropriate use of average graph metrics or summary statistics to compare networks; although this approach is useful when comparing a network to a null model, using such univariate analyses for group comparisons takes away much of the benefits of network analysis. The rationale for using network science in the brain is to understand the organization and dynamics of the brain as a complex system.
Reducing characteristics of a network to a single value renders a poor and often misleading guide for understanding complex systems. Another fundamental problem with such an approach is that measurements within a network are not independent. A measurement at a given node is typically affected by distant nodes. Taking degree as an example, removal of an edge affects two nodes. Likewise, metrics such as clustering coefficient are dependent on the connectivity of neighboring nodes. Slight changes in connectivity patterns can greatly affect the measurements made at a particular node; thus, no nodal measurement in a network is completely independent.
Various studies have reported differences in clustering, path length, and efficiency from a range of diseases and disorders including Alzheimer's disease Lo et al. In two separate studies on epilepsy, one group reported lower path length between patients with epilepsy and the control group Liao et al. Further inquiry to determine the direction of global changes in the network neglects the bigger question: Does the direction of change imply that the network has entered a particular disease state? For example, is lower path length a sign of depression or multiple sclerosis?
Although differences can be found using these metrics, their lack of specificity implies that researchers should not rely on global metrics. Due to this, massively univariate analysis methods widely used in functional neuroimaging analyses should not be applied to brain network data.
Aligning with the combined strengths of the INI and in collaboration biomedical and electrical engineering groups my long-term vision is to extract fundamental principles of network-learning from real biological networks and then to reverse engineer their functionality as logical, reproducible algorithms that be implemented in software or directly as electrical circuits.
I am convinced that reverse-engineering neural learning algorithms that mimic human thinking will one day change the importance of intelligent technologies in our everyday life. We research sensorimotor and observational learning, birdsong development, neural coding in auditory and motor brain areas, ultrastructure of synaptic networks.
We make use mainly of computational modeling, behavioral methods, electrophysiology, and light- and electron microscopy. The neuromorphic cognitive systems we develop are typically real-time behaving systems comprising multi-chip, multi-purpose spiking neural architectures. They are used to validate brain inspired computational paradigms in real-world scenarios, and to develop a new generation of fault-tolerant event-based computing technologies.
Within the neuroscience field, we focus on transport processes in the fluid spaces of the brain, namely in the cerebrospinal, interstitial and perivascular fluids. By combining computational techniques with experimental methods, we aim to understand the dynamics of cerebral fluid motion, the driving forces behind these and how they, along with the associated transport processes of metabolites and other substances, are involved in the pathogenesis of CNS disorders.
Our lab develops and obtains new neurophysiological and neuroimaging measures in the context of human brain and behavioral plasticity. Specifically, we investigate the potential for plasticity, mechanisms for stabilization and compensation across the lifespan. In particular, we investigate the relationship between brain plasticity and cognitive functioning, such as perceptual processing, learning, working- memory, decision-making and processing speed. In this context of neuroplasticity research, we are designing and implementing novel multi-modal paradigms e. These paradigms can also be used to decompose the critical component processes underlying performance of the behavioral tests that are used routinely in clinical diagnosis.
This multi-level, multi-modal design allows us to study cognitive performance and perception at their desired level of analysis, and to elucidate variations in performance across the continuum from healthy to pathological functioning.
I co-lead the sensors group at INI. Our group develops neuromorphic silicon cochlea and retina sensors and methods for processing their output. My focus is on the design of silicon spiking cochleas such as the AEREAR2 cochlea, and the development of real-time event-driven auditory processing algorithms and networks for tasks such as classification and recognition, and together with the dynamic vision sensor DVS in tasks such as sensory fusion tasks.
These sensors and processing methods are inspired by the organizing principles of the nervous system. We also look for neural electronic equivalents of these algorithms through implementations in FPGA or in custom silicon, for example, silicon dendritic circuits and in the process, we hope to develop an understanding of some of the principles used in our brains for processing information.
One of the most fascinating properties of the brain is its ability to extract relevant information from the environment e. However very little is known about how this feature extraction is performed in the brain. I am particularly interested in better understanding how this feature extraction is implemented at the level of neurons and synapses. More generally, I am interested in developing new statistical models and apply them in the field of neuroscience. This statistical approach in neuroscience is mainly focused at the level of spiking neurons. Humans do not react to the environment in a reflexive manner, but can freely choose which action to perform in response to a given situation.
The neural processes that enable such flexible decision making are fundamental components of human cognition and have attracted a lot of interest from researchers in many scientific disciplines such as neuroscience, psychology, economics, and medicine.
The research agenda at the Decision Neuroscience Lab bridges these multiple disciplines across theoretical and empirical domains to establish important links between the computational, psychological and neural processes controlling human decision making, by providing both correlative and causal evidence that well-defined neural signals are indeed driving both computationally defined cognitive processes and the resulting behavior.
This research thus has the potential to unite conceptually separate approaches to the study of distinct types of human behavior and thereby contribute information that is crucial for the diagnosis and treatment of psychiatric and neurological disorders involving decision-making pathologies e. Emotions, comparative neuroscience, computational modelling, fear conditioning, anxiety Topics: Neural algorithms and behaviour How does the brain solve complex problems? Neural basis of behaviour, computation and modelling, molecular and cellular neuroscience, disorders of the nervous systems Publications: Computation and Modeling Website: Sensory Systems, Computation and Modeling Publications: I am convinced that reverse-engineering neural learning algorithms that mimic human thinking will one day change the importance of intelligent technologies in our everyday life Keywords: Neuromorphic, learning, plasticity, attention, electronic circuits Topic: